Projects
View all projects from the Amsterdam University of Applied Sciences. Looking for a particular project? Click the magnifying glass at the top of the page to search.
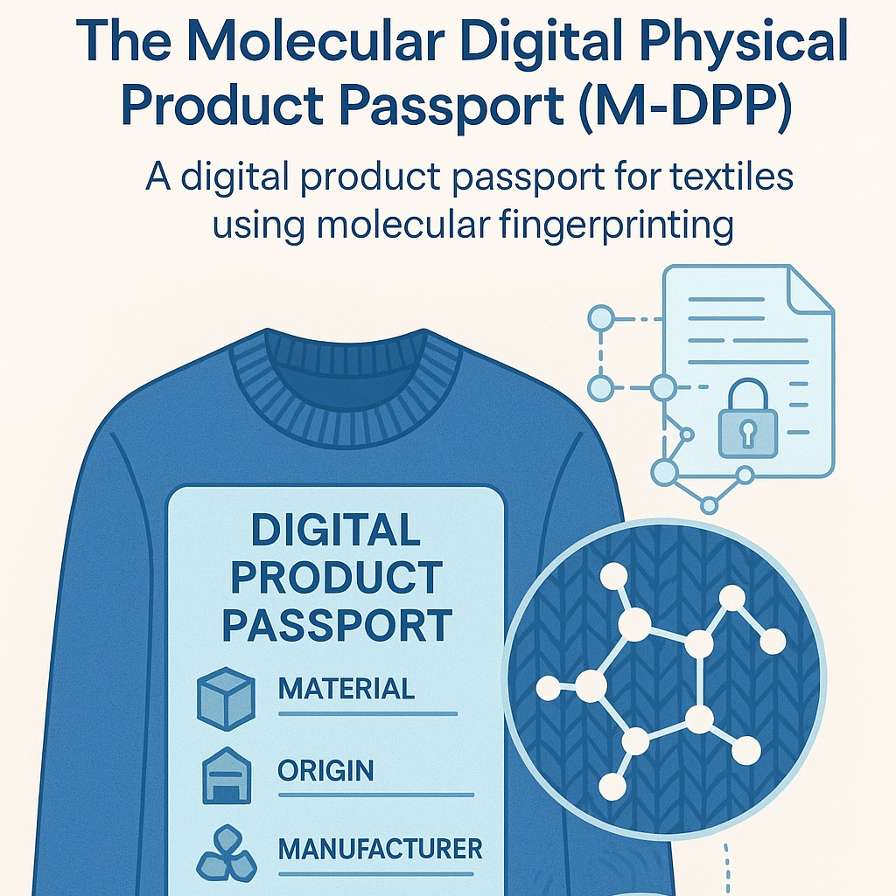
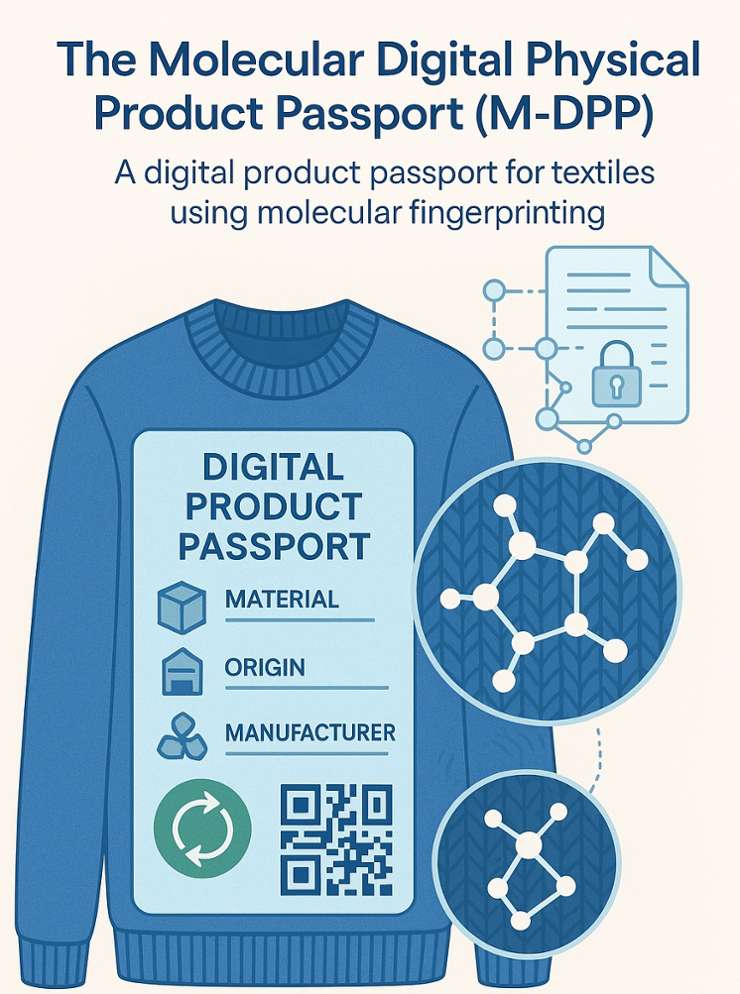
M-DPP-Digital passports for traceable fashion
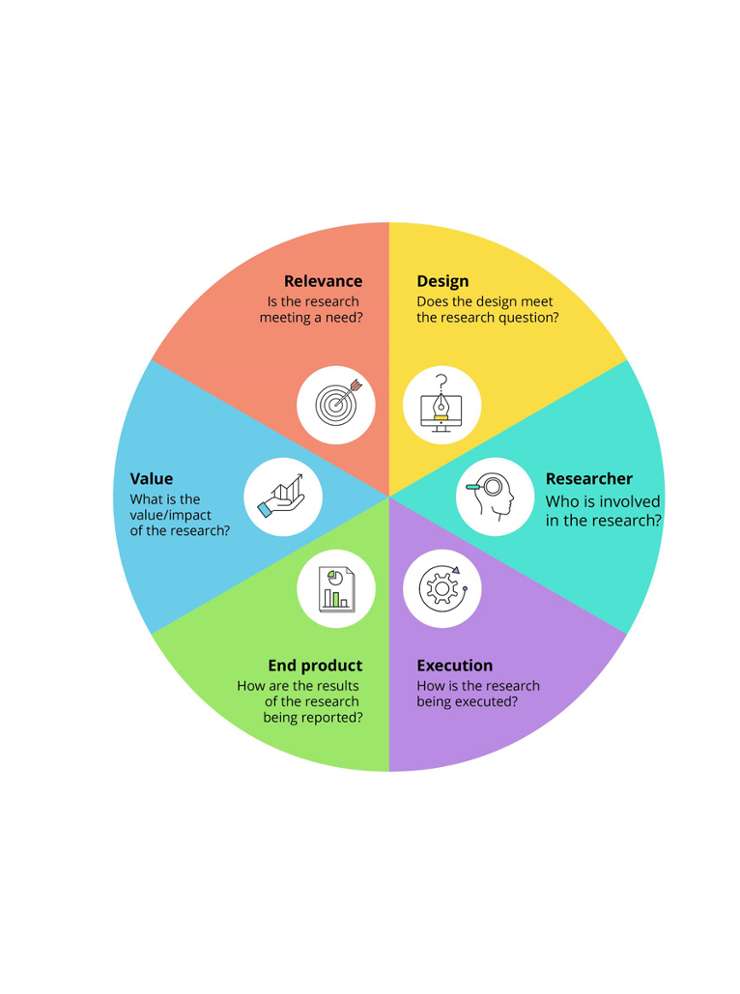
Creating the Desire for Change in Higher Education - Tools
UrbanSWARM: Nature-Based Solutions for Circular and Future-Proof Cities

Keeping it Local

ReFan: Reshaping the Fashion Narrative

Generative AI Agent(s) for policy officers

Spirit: Collaborating for person-centred care through integrated, robust, and innovative technology
Intercultural Chatbots: Using Generative AI to Enhance Intercultural Learning

Care & Repair

Ground for Wellbeing

Fair fashion

U!Innovate: Empowering Climate and Neutral Innovations

What if AI...?
Storytelling for Collective Care in our Neighborhoods

Understanding Durability in Circular Business Models (DURBUS)

Urban Upcycling: High-quality reuse of residual flows